Why Context Engineering Is Becoming the Full Stack of AI Agents

AI agents are everywhere in 2025—almost every company is building chatbots, coding assistants, and knowledge bases at breakneck speed. Building a cool demo is easy, but taking an agent from demo to a reliable, production-ready system is a different challenge. And almost every team that makes that leap runs into the same roadblock: context.
Your chatbot can’t see your customer history. Your coding assistant doesn’t understand your codebase. Your business AI can’t tap into real-time data or take meaningful action…
To work around this problem, teams have tried all kinds of fixes: carefully crafted prompts, sophisticated RAG implementations, 128k+ context windows, and standardized protocols like MCP to connect components.
All of these work. But they’re often siloed—developed and deployed independently. We end up with brittle systems that solve one piece of the puzzle but don’t give the AI a complete picture.
What if context wasn’t an afterthought? What if it was the foundation? That’s where Context Engineering comes in.
How to Understand “Context” in AI Agents
Before we dive into context engineering, we need to get clear on what “context” actually means—especially when building a reliable AI agent.
Context isn’t just the single prompt you send to an LLM. It’s everything the model sees before it generates a response. The more relevant and higher-quality the context is, the better the output and the smarter the agent’s actions. And the reverse is just as true: garbage in, garbage out.
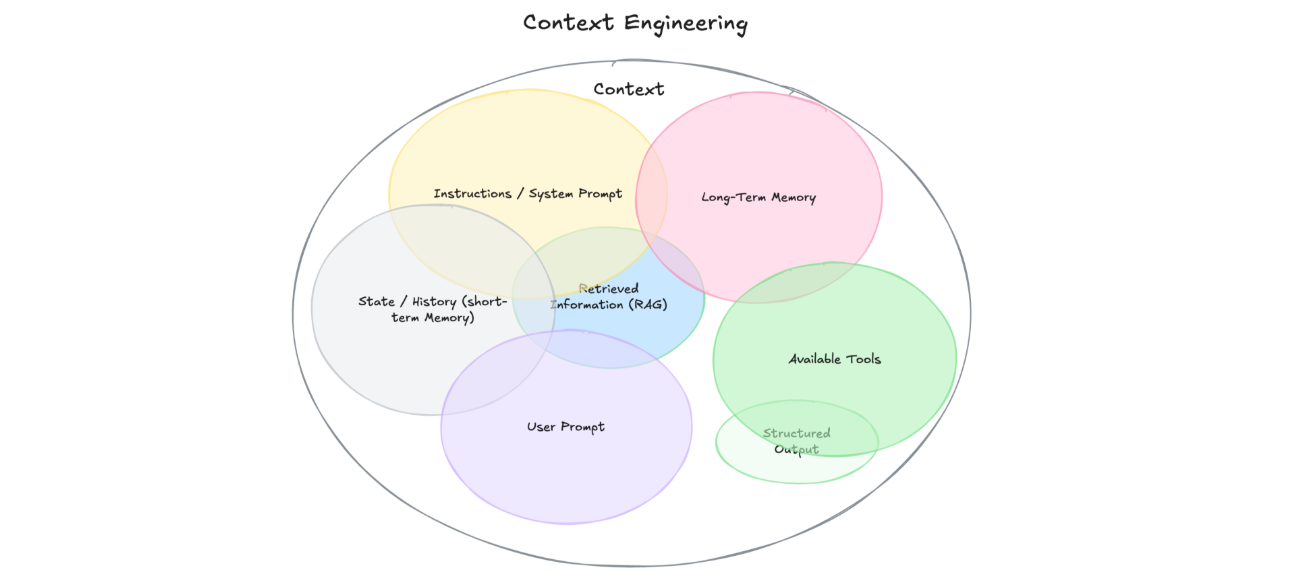
In agentic AI systems, context comes from multiple sources—most of which current systems struggle to coordinate effectively:
Instructions / System Prompt – The initial rules that shape the model's behavior, often with examples and constraints (e.g., "Act as a technical support agent with access to our knowledge base")
User Prompt – The immediate task or question from the user ("My API calls are failing with 503 errors")
State / History (Short-Term Memory) – The conversation so far, including both user and model messages
Long-Term Memory – Persistent knowledge gathered across many interactions, such as user preferences, summaries of past work, or remembered facts
Retrieved Information (RAG) – Relevant, up-to-date knowledge pulled from documents, vector databases like Milvus, or APIs (recent documentation, similar resolved issues)
Available Tools – Functions or built-in capabilities the model can call (e.g., check_system_status, create_support_ticket, escalate_to_engineer)
Structured Output Definitions – Expected formats for the model's response, such as JSON schemas or specific formatting requirements
 context engineering.png
context engineering.png
Image Credit: Philschmid
The challenge? Most agents operate with only 20-30% of the context they could have—and it shows in their performance. They give generic responses when they should be personalized, suggest outdated solutions when fresh information exists, or fail to take action when they have the tools to help. Context engineering is about closing that gap.
So, What’s Context Engineering?
Since context is everything an AI needs to perform well, context engineering is the discipline of designing systems that ensure the model gets it—all of it, in the right format, at the right time.
This term might be new, but the idea isn’t. We’ve been moving toward it for years—just without giving it a name. Techniques like RAG, prompt engineering, function calling, MCP, and others are all pieces of the puzzle. Context engineering is about putting those pieces together into a coherent whole.
Think of it as the new full stack for building agentic AI. If traditional full-stack development connects the frontend, backend, and database into a working application, context engineering connects knowledge, tools, and reasoning into a seamless intelligence layer that agents can actually work with.
At its core, context engineering is about three key principles:
Dynamic adaptation – Context shapes itself to the current task and system state, not just static templates
Just-in-time assembly – The right information and tools arrive precisely when needed, not dumped all at once
Optimal formatting – Everything is structured so the LLM can understand and act on it effectively
When you treat context as infrastructure—not just text you drop into a prompt—you create agents that can reason about complete situations, take meaningful actions, and improve their performance over time.
How Context Engineering Differs from Prompt Engineering and RAG
Even after understanding context and context engineering, it’s easy to confuse them with prompt engineering or RAG—they share some techniques, but the scope and goals are different.
Prompt Engineering – The art of crafting inputs that guide an LLM’s behavior. This includes few-shot examples, role-play, formatting rules, and tone control. It’s powerful for shaping responses, but it can’t add missing knowledge or trigger real-world actions.
RAG (Retrieval-Augmented Generation) – One of the first solutions to reduce hallucination. It fetches relevant documents from a vector database (like Milvus) and injects them into the prompt at runtime. While great for keeping the model up to date, it focuses only on adding external knowledge—not managing task state, user preferences, or tool use.
Context Engineering – The umbrella discipline. It unifies retrieval, prompt design, tool orchestration, and dynamic adaptation into a single, engineered system. The goal is to ensure the agent always has the right information, tools, and formats—at the right time—to act effectively.
Think of it like this: prompt engineering is giving clear instructions, RAG is supplying the right ingredients, and context engineering is running the whole kitchen.
How Vector Databases Power Context Engineering
If context engineering is the new full stack, vector databases are its database layer—or long-term memory. That’s because the most relevant context for an AI agent almost always lives outside the LLM’s training data—in places like customer support transcripts, code repositories, knowledge base articles, sensor readings, and even images or audio files.
A vector database stores this information as embeddings, enabling semantic retrieval—finding what’s relevant based on meaning, not just keyword matches. This is critical for context engineering because it ensures the agent gets precisely the information it needs, exactly when it needs it.
Here’s how vector databases power context engineering:
Dynamic vector retrieval – Surface context relevant to the current task in real time, using semantic similarity rather than simple keyword search.
Multimodal support – Store and retrieve text, images, audio, video, or even embeddings from structured data in one system.
Freshness and updates – Keep the AI’s “working memory” current without retraining, enabling agents to adapt to new information instantly.
Scalability – Handle billions of vectors without degrading performance, supporting enterprise-scale deployments.
In a context-engineered system, vector databases don’t work alone. They operate alongside:
A prompt construction layer that formats retrieved data for the LLM.
A tool invocation layer that enables actions beyond text generation.
A feedback loop that refines retrieval and tool use based on results.
This turns the vector database from a passive storage engine into an active part of the agent’s reasoning process—not just answering queries, but shaping the decisions the agent makes.
Why Milvus Fits Perfectly into Context Engineering for Production Agents
When it comes to powering context engineering, particularly for building production-level AI Agents, not all vector databases are equal. You need a system that can handle huge volumes of embeddings, adapt to multiple data modalities, and deliver results in milliseconds—without becoming a bottleneck. That’s where Milvus comes in.
Milvus is an open-source vector database designed from the ground up for high-performance semantic search at scale. It’s built to store, index, and retrieve billions of vectors efficiently, making it ideal for scalable, production-level AI agents that depend on timely, high-quality context.
Here’s why Milvus stands out for context engineering:
Scale without compromise – Whether you’re indexing millions or billions of vectors, Milvus maintains low-latency retrieval for real-time applications.
Multimodal ready – Handle text, images, audio, video, and embeddings from structured data in one system.
Flexible deployment – Run it on your own infrastructure or in the cloud with Zilliz Cloud for a fully managed, hassle-free experience.
Rich ecosystem – Integrates seamlessly with RAG frameworks, AI development tools, and your existing data pipelines.
Hybrid search excellence – Combine semantic similarity with metadata filters and keyword search for complex business queries like "Find pricing documents John accessed in the last two weeks mentioning API rate limits with positive customer sentiment"
In a context-engineered architecture, Milvus is more than a data store—it’s the engine that ensures your AI agent always has the right knowledge at its fingertips. And when you pair it with Zilliz Cloud, you get enterprise-grade reliability, elasticity, and global availability, without having to worry about cluster management or scaling headaches.
Ready to Build Smarter Agents with Better Context?
The smartest AI agents aren’t powered by the biggest models—they’re powered by the best context. Context engineering makes it possible, and it starts with a robust vector database you can trust.
Milvus gives you open-source freedom and billion-scale performance. Zilliz Cloud takes it further with a fully managed service built on Milvus—enterprise-grade reliability, elastic scaling, and zero infrastructure headaches.
🚀 Get started your way:
Run Milvus locally or in your own environment.
Or try Zilliz Cloud for free with $100 in free credits—no setup, no ops.
You can also reach out to us to see what purpose-built vector infrastructure can do for your AI agents.
💡 Already using Pinecone, Weaviate, pgvector, or another platform? We can help you migrate smoothly with zero downtime, often at half the cost you’re paying now—and with better performance.
 Fendy Feng
Fendy FengFendy Feng is the Technical Marketing Writer at Zilliz. She has extensive experience developing and enhancing the impact of open-source projects in various global markets by producing high-quality, tailored content. Before joining Zilliz, Fendy worked as a Content Strategist at PingCAP, a fast-growing E-Series startup renowned for its open-source distributed SQL database.
- How to Understand “Context” in AI Agents
- So, What’s Context Engineering?
- How Context Engineering Differs from Prompt Engineering and RAG
- How Vector Databases Power Context Engineering
- Why Milvus Fits Perfectly into Context Engineering for Production Agents
- Ready to Build Smarter Agents with Better Context?
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

How to Build RAG with Milvus, QwQ-32B and Ollama
Hands-on tutorial on how to create a streamlined, powerful RAG pipeline that balances efficiency, accuracy, and scalability using the QwQ-32B model and Milvus.

Introducing DeepSearcher: A Local Open Source Deep Research
In contrast to OpenAI’s Deep Research, this example ran locally, using only open-source models and tools like Milvus and LangChain.

Building Secure RAG Workflows with Chunk-Level Data Partitioning
Rob Quiros shared how integrating permissions and authorization into partitions can secure data at the chunk level, addressing privacy concerns.